

 sales@resultfirst.com
sales@resultfirst.com
12 Ecommerce SEO Gaps Claude Finds That Internal Teams Miss Without Agency Help

Running a Claude SEO audit on an eCommerce site is fast. The output is specific. And for most in-house teams, it is the beginning of a problem they did not fully anticipate.
The audit comes back with a list. Missing schema on product pages. Canonical errors across faceted navigation. Thin category descriptions. Author attribution absent on every blog post. Internal links pointing nowhere useful. The score reads 4/10 for AI citability and the technical checklist has more red than green.
The team reads it, nods, and then the calendar fills up with other priorities.
This is not laziness. It is a resource problem. A Claude audit run on a store with 40,000 SKUs produces findings that require weeks of coordinated work across developers, content writers, and product data teams, all running simultaneously, all without disturbing live rankings or breaking the catalog. That is not a prompt problem. It is an operations problem.
Below are the 12 gaps Claude consistently flags on eCommerce sites, what each one means for revenue, and why in-house teams stall on every one of them.
1. Missing or Incomplete Product Schema
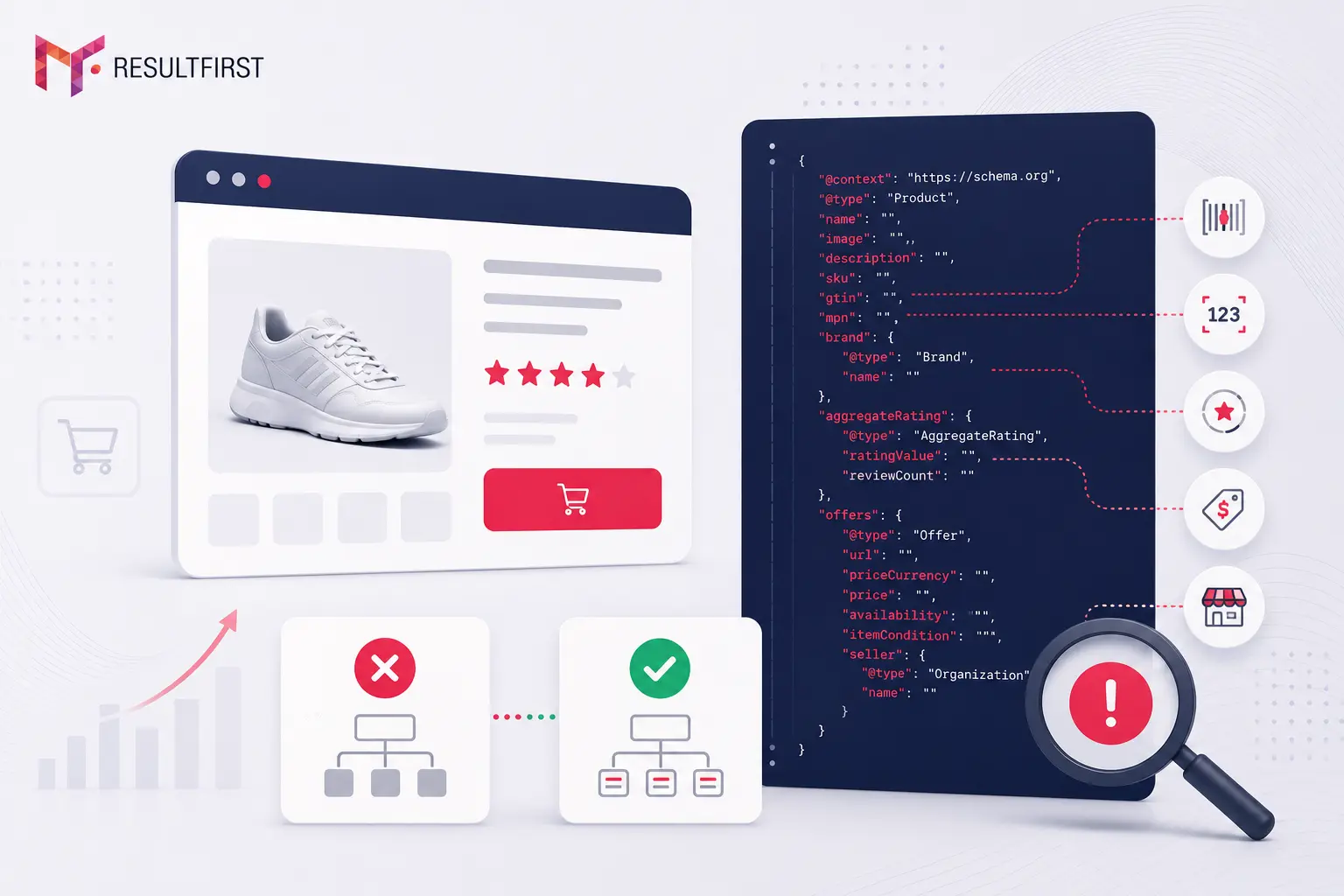
Pages with schema markup achieve 20 to 40% higher click-through rates than pages without it, according to research compiled by Bloggers Ideas (2026). Yet most eCommerce sites are running generic or platform-default schema that leaves out the fields that matter most for both Google Shopping and LLM citations: gtin, mpn, aggregateRating, review, brand, and specific offer details.
A February 2026 study found that generic Product schema produced no measurable lift in AI Overview citations, while attribute-rich Product schema that included complete specification fields showed meaningful improvement in citation rates. Claude flags this gap on almost every catalog it audits.
The fix requires building a schema implementation that validates across the full product catalog in real time, adapts to new Schema.org releases, and does not break on the next platform update. At catalog scale with significant SEO traffic, the gap between platform-default schema and a fully engineered implementation translates to 15 to 30% more rich result coverage, according to Xenara’s measurements across their eCommerce clients.
2. Faceted Navigation Creating Crawl Waste
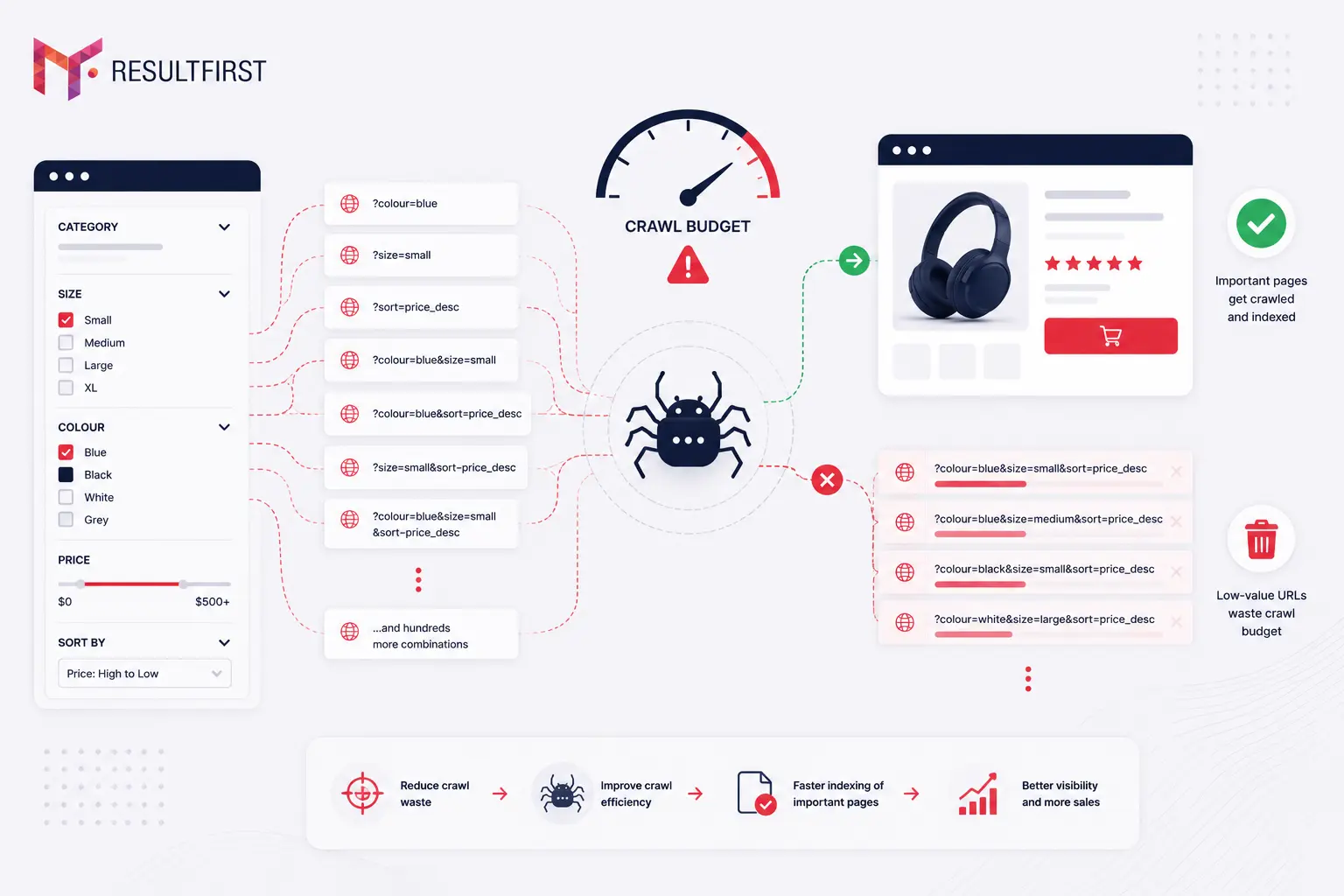
A store with 10,000 products and 50 filter options can generate over 100 million URL combinations, most of which are near-duplicate pages that destroy crawl budget and dilute link equity (Digital Applied, 2026).
Faceted navigation is the single largest crawl budget problem for eCommerce sites. When users filter by size, colour, or price, most CMS platforms generate a new URL for each combination. Google ends up crawling ?colour=blue&size=small&sort=price_desc instead of your new high-margin product launch.
The problem has compounded in 2026. AI crawlers now account for roughly 22% of bot traffic according to Cloudflare’s Q1 2026 data, and ClaudeBot crawls around 50,000 pages for every referral it returns. Faceted URL sprawl is now wasting both Google’s crawl budget and the AI crawler budget that determines whether your products get cited at all.
Fixing this requires a decision framework applied across every filter type: canonical tags for signals consolidation, robots.txt blocking for zero-SEO-value parameters, noindex for pages that exist for users but not for search engines. Getting this wrong causes ranking losses that take months to recover. Getting it right on a live catalog with 500,000 URLs is not a one-afternoon task.
3. Orphaned Product Variant Pages
Product variants are one of the most persistent thin-content problems in eCommerce SEO. When each colour or size variation of a product gets its own URL with near-identical content, the result is a cluster of pages competing against each other for the same query, none of them strong enough to rank well.
Claude flags these as both a duplicate content issue and a GEO problem. LLMs cannot form a confident citation for a product that appears across 14 near-identical pages with no clear canonical hierarchy. The AI sees conflicting signals and skips the brand entirely.
The fix is grouping variants under stronger parent products with explicit schema relationships and proper canonicalization, while ensuring the parent page carries enough specification depth, review data, and use-case content to satisfy both Google and LLM evaluation. This requires both a technical and an editorial decision for every product category.
4. Thin Category Page Descriptions
Category pages are the highest-revenue pages on most eCommerce sites. Well-optimized category pages typically generate 3 to 5 times more organic revenue than individual product pages because they rank for high-volume head terms and capture buyers earlier in the purchase journey.
Yet the default behaviour for most themes and platforms is to render a category page as a product grid with no descriptive content. Category pages with 150 to 300 words of unique descriptive content rank 2.7 times higher than pages with product grids alone, according to the same research.
Claude flags thin category descriptions as a GEO failure too. A category page with no introductory content, no FAQ structure, and no entity signals gives LLMs nothing to cite when a buyer asks a conversational question about that product category. You rank for the category query. You still get skipped in the AI answer.
Writing unique, substantive category descriptions across hundreds of category pages, maintaining them as inventory changes, and ensuring they address buyer intent rather than just listing product names is a content operations challenge that most in-house teams do not have the bandwidth to sustain.
5. Broken or Missing Canonical Tags
As of 2026, studies indicate that 53% of eCommerce sites are missing canonical tags. On sites with faceted navigation, pagination, session IDs, and sorting parameters, canonical errors allow search engines to crawl hundreds of versions of the same page and consolidate signals on the wrong one.
The deeper problem is that canonical errors compound silently. A product page that should be accumulating link equity and authority is instead splitting it across six URL variants. Rankings plateau without any obvious explanation. The fix requires a canonical audit that maps every URL family, validates canonical chains, and ensures sitemaps contain only the canonical, 200-status, indexable URLs that actually need to rank.
6. Missing AggregateRating and Review Schema
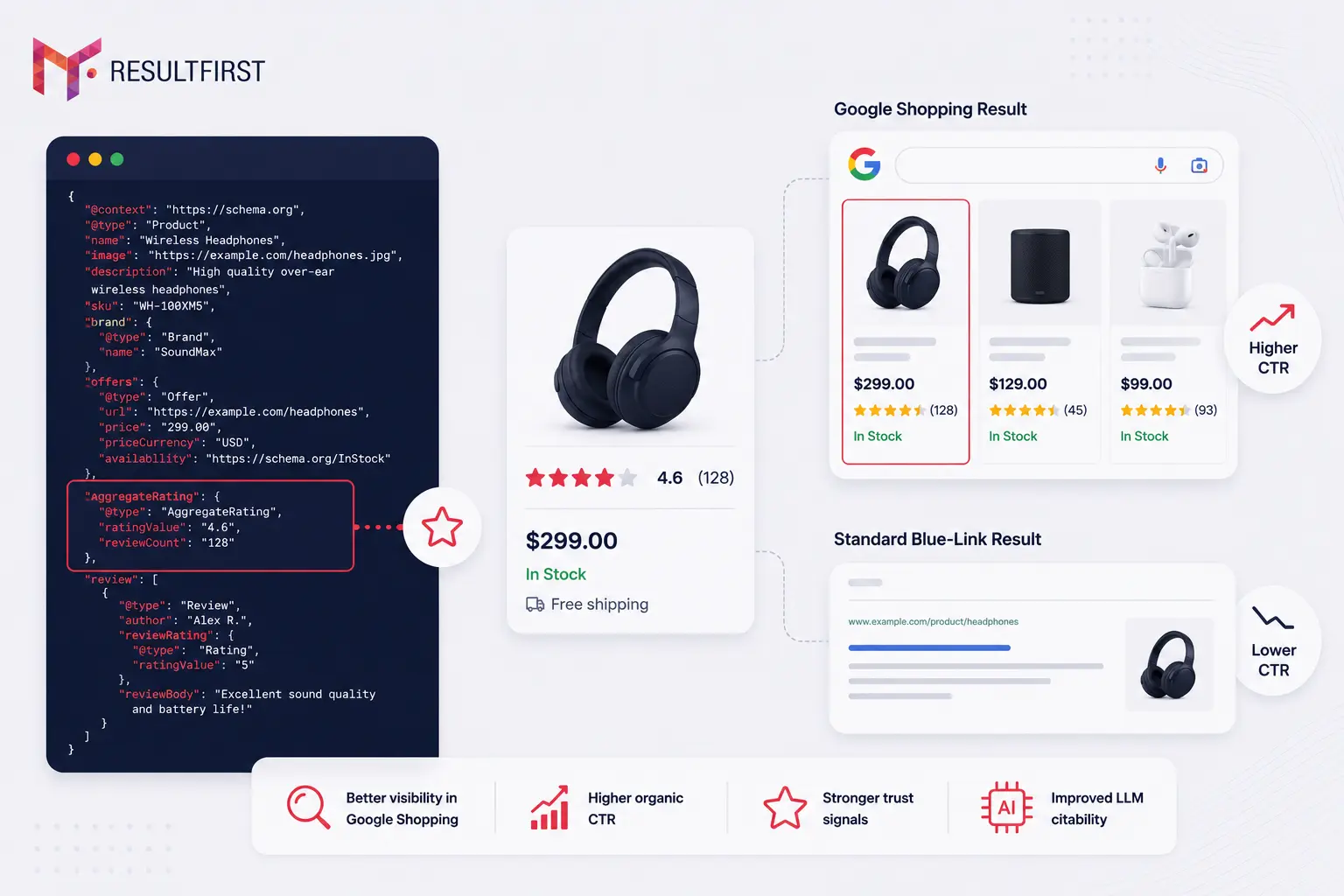
Review signals matter for both traditional search and LLM citability. Enabling price, rating, availability, and review count in Google Shopping results increases organic CTR by an average of 30% compared to standard blue-link results.
For LLM citations specifically, review schema is a trust signal that tells the model this product has been evaluated by real buyers. XLR8 AI’s data from tracking 606,489 citations across eCommerce queries confirms that brands with well-formed AggregateRating schema earned measurably higher citation share across ChatGPT, Claude, and Perplexity.
Most eCommerce platforms either do not output review schema by default or output it incorrectly. Validating and correcting this across a full product catalog requires schema engineering, not just configuration.
7. Slow Core Web Vitals on Product and Category Pages
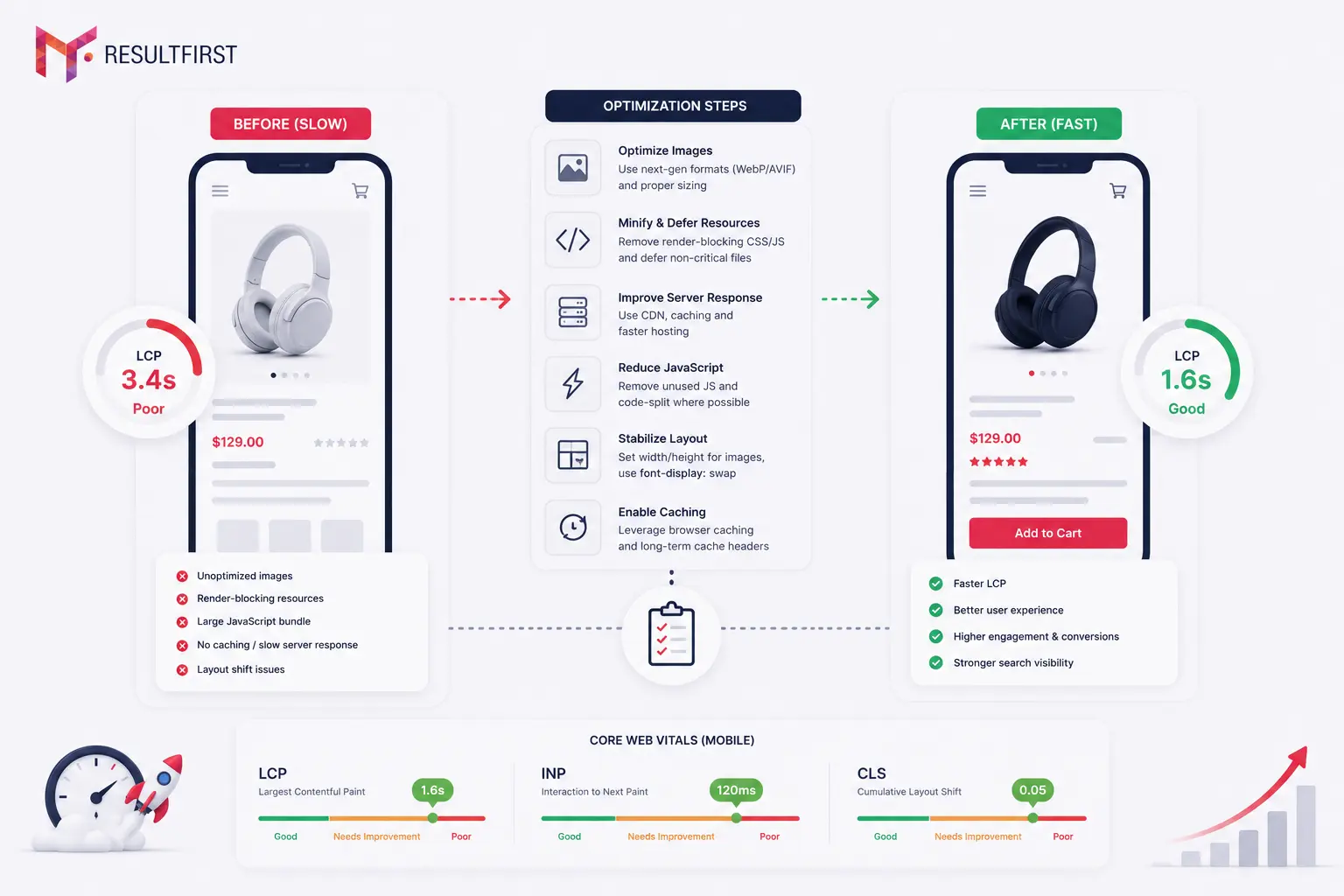
Only about 39% of websites pass all three Core Web Vitals on mobile. This matters more than almost any other technical metric because Google lowered the Good LCP threshold from 2.5 seconds to 2.0 seconds in the March 2026 core update, and sites with LCP above 2.5 seconds saw average ranking drops of 2 to 4 positions.
The financial case for fixing this is not abstract. According to the Google and Deloitte joint study “Milliseconds Make Millions,” every 0.1 seconds of improvement in site load speed increases conversions by 8% in retail. For a store generating $5 million annually, a 500ms load time improvement translates to roughly $400,000 in recovered revenue.
The problem is that the primary causes of slow eCommerce pages, namely heavy product images, dynamic banners, resource-intensive interactive filters, stacked third-party scripts, and unoptimized JavaScript rendering, all require developer time to fix. In-house teams often identify the problem through Claude’s audit. Fixing it requires coordinated front-end engineering work that competes with every other development priority on the roadmap.
8. Internal Link Dilution Across Large Catalogs
Strong internal linking can boost search rankings by up to 40%, improve crawl efficiency by 40 to 70%, and drive traffic increases of 30% or more, according to research compiled by. Pages with 5 to 10 well-placed internal links perform approximately 25% better than those with fewer connections.
The default failure mode in eCommerce is category pages that link to dozens of products but carry no editorial context, while high-value product pages sit with no internal links pointing to them from relevant blog content or related category pages. Claude identifies these orphaned pages and diluted hub pages as both a crawl efficiency problem and an authority consolidation problem.
Building and maintaining a meaningful internal link structure across a catalog that changes with inventory, seasonality, and promotions is not a one-time task. It requires an automated system with commercial logic built in, a link to a high-margin product category should be weighted differently than a link to a clearance section.
9. Absent Author Attribution Across Blog Content
Claude evaluates author credibility as part of its E-E-A-T assessment. It looks for author bylines, linked author bios, Person schema, external mentions of the author by name, and consistent authorship signals across the domain. Most eCommerce brands publish buying guides, trend pieces, and product comparison content anonymously, with no author attached.
Anonymous content fails LLM citability checks because the model has no way to validate the expertise behind the claim. A buying guide that recommends a product means more when it is attributed to someone with demonstrable knowledge in that category. Without attribution, Claude treats the content as unverifiable and skips it in favour of sources with clearer authority signals.
Retrofitting author attribution across existing blog archives, building out author bio pages with Person schema, and creating a governance system to ensure new content always carries attribution is an editorial and technical operation that requires more than just adding a name to a byline.
10. Unstructured Product Feed Data That LLMs Cannot Read
LLMs treat structured data as first-class citizens. A paragraph full of adjectives describing a product is invisible to the evaluation system Claude uses when deciding whether to recommend it in response to a specific buyer query. What the model needs is technical specificity: dimensions, materials, compatibility, certifications, use-case attributes, and availability signals formatted in machine-readable structured data.
Traffic from generative AI sources to US retail sites grew 4,700% year-over-year according to Adobe’s analysis as reported by Triple Whale (2026). That traffic goes to the brands whose product data is structured clearly enough for LLMs to read and cite confidently. Shoppers arriving from generative AI sources spend 32% longer on site and have 27% lower bounce rates compared to traditional channels, according to the same research from Envive AI’s LLM discoverability trends analysis.
Restructuring a product feed to provide this level of technical specificity across a catalog of 10,000 or more SKUs is a data architecture project, not a content task.
11. Image Alt Text Gaps and Missing Image Schema
Image alt text is one of the most frequently skipped SEO tasks in eCommerce. At catalog scale, product images are often uploaded by operations teams with file names that look like IMG_4923.jpg and alt text left blank. This creates accessibility failures, missed keyword signals, and lost eligibility for Google Image search traffic.
For LLM visibility, image schema matters because it contributes to the overall structured data picture the model uses to assess whether a product page is citation-worthy. A product page with strong text content but missing image signals is an incomplete entity in Claude’s evaluation model.
Auditing and correcting alt text across thousands of product images requires both automation and editorial review. Automated tools can identify the gaps. Writing accurate, specific alt text that serves both accessibility and SEO for each product variation is a content task that requires category knowledge.
12. Missing or Malformed FAQ Schema on Product and Category Pages
FAQ schema serves two purposes in 2026. For traditional search, it supports rich results that increase SERP real estate and click-through rates. For LLM visibility, it directly signals to Claude and other language models that this page answers specific buyer questions in a structured, verifiable format. Pages with FAQ schema are more likely to be cited in AI-generated answers because the question-and-answer structure matches exactly how LLMs retrieve and present information.
The gap on most eCommerce sites is that FAQ sections exist as plain HTML text with no structured markup, or they do not exist at all on product and category pages where buyer questions are most common. Claude flags this consistently as a missed citability opportunity.
Writing and structuring FAQ content that addresses genuine buyer questions, adding correct FAQPage schema, and validating it across product and category page templates is a content and technical task that requires coordination between editorial and development teams.
What the Pattern Tells You
Running through this list, the theme is consistent. Claude can identify every one of these gaps in a single audit session. What it cannot do is fix any of them.
Schema remediation across a 40,000-SKU catalog requires a development sprint, a validation pipeline, and ongoing monitoring. Canonical audits on a site with faceted navigation require a URL decision framework applied consistently across every filter combination. Author attribution across a three-year blog archive requires editorial governance and Person schema implementation. Internal link architecture across a live, changing catalog requires commercial logic that no prompt can build or maintain.
The audit is the easy part. Execution is where most in-house teams run out of road.
The Demand Picture From 2026 Onward
These gaps are not getting easier to manage. The AI shopping market is projected to reach $74 billion by 2034, growing at a compound annual growth rate of 23.6% from its current $7.25 billion base, according to Precedence Research as cited by Triple Whale (2026). Retail and eCommerce is projected to account for 25 to 27.5% of the global enterprise LLM market in 2026, according to Bloomreach’s LLM market analysis.
What that means for eCommerce brands is straightforward. The brands closing these 12 gaps now are building the structured data foundation and entity authority that will determine their AI search visibility for the next five years. The brands that leave these gaps open are not just losing current traffic. They are making their future recovery harder and more expensive with every month that passes.
By 2027 and 2028, agentic commerce will begin to shift the buyer journey further. Shoppers will not be clicking through search results or even asking Claude a question manually. AI agents will be completing purchases on their behalf based on product data their model already trusts. The brands whose structured data and entity signals are already built into that trust layer will capture the transaction. The ones who are not in the model’s citation pool will not be considered.
Why eCommerce Brands Work with ResultFirst
The 12 gaps above are not discovery problems. Every eCommerce team with access to Claude or any competent audit tool already knows most of them exist. The problem is execution at scale, without disrupting live rankings, within a development roadmap that has competing priorities and a content team that is already at capacity.
ResultFirst’s eCommerce SEO services are built specifically around this execution gap. Our pay-for-performance model means you are not paying for an audit report that collects dust. You are paying for rankings that move, schema that validates across your full catalog, and structured content that earns LLM citations alongside traditional search visibility.
We bring the technical infrastructure to handle schema at catalog scale, the editorial framework to build citation-worthy category and product content, and the GEO and enterprise SEO expertise to close the gap between what Claude finds and what actually gets fixed.
The audit tells you where you are. A performance partner gets you where the revenue is.
If your analytics are starting to show the patterns described in this piece, flat or declining organic traffic, LLM referral data going to competitors, product pages that rank but do not get cited in AI answers, the right next step is a structured assessment of your current gaps, not another tool run.
The ResultFirst team works with eCommerce brands at exactly this level of specificity. Reach out to start that conversation.
Sources Referenced:
- Bloggers Ideas: E-Commerce SEO Statistics 2026
- Charle Agency: 60+ eCommerce SEO Statistics for 2026
- Digital Applied: eCommerce SEO Product and Category Page Guide 2026
- https://ahrefs.com/blog/schema-ai-citations
- https://blog.cloudflare.com/ai-crawler-traffic-by-purpose-and-industry
- Upward Engine: Internal Linking Best Practices for SEO 2026
- Triple Whale: AI in eCommerce Statistics 2026
- Bloomreach: Large Language Models in the Future of eCommerce
- Envive AI: 20 LLM Product Discoverability Trends for eCommerce
WHAT TO READ NEXT
READY TO BUILD PREDICTABLE ORGANIC GROWTH?
We are the only TOP SEO services agency providing Real Results in a Real Performance model. We help growth hungry companies outperform their competition and achieve 300%+ growth in their digital marketing initiatives.
- San Jose, CA, 95120

- +1-888-512-1890

- sales@resultfirst.com

300K+
KEYWORDS RANKED
546M+
REVENUE GENERATED
18 Years
SOLVING COMPLEX SEO
150+
TEAM MEMBERS







